
AI may seem like magic a lot of the time, but it isn’t. AI is really just sophisticated probabilities: aka math! As AI does more and more, we shouldn’t just assume all is good. Sometimes the math just doesn’t add up, and being wrong might have dire consequences. But, how do those of us without PhDs know our AI is high quality? Let us explain.
We’ll start with a quick example then detail out how quality can be delivered by applying rigor throughout AI’s lifecycle—from the data used, to how it is measured, to how it is used.
A simple example
Let’s use a very simple example of recognizing dogs from cats using supervised learning—when all the data is labeled. Let’s assume you start with 1,000,000 pictures of cats and dogs (yes, social media is full of them). Of course, you would want to review the data not only to label it correctly but to also curate it—are there dogs and cats from various breeds, in different colors, sizes, and positions, with various backgrounds, etc. Obviously, training a model on only seated Yorkies with grass backgrounds would not lead to a robust model.
Next, you would set aside a random ~30% of the pictures and train the models on the remaining ~70%. Once the model is trained, you would have it process the pictures it never saw before to see how it does. Did it accurately sort dogs from cats when shown new data? Did the model perform the task correctly?
Then let’s assume this model is used by a company that sorts photos for pet adoption sites, putting the dog photos in the dog section and cat photos in the cat section. As the model is being used in the real world with new data it has never seen, even the best models will sometimes get it wrong. It is important that humans provide feedback, called “human in the loop.” When the model gets it wrong, the end user can provide input, allowing the model to learn and get better and better.
This very simple example highlights some of the keys to quality models: data, fit, feedback. Let’s discuss each.
The importance of data
The process of cleaning, organizing, and transforming data before using it for AI model training is crucial since the accuracy of a model is directly linked to the quality of the underlying data (read more on the importance of data). It is important to understand what data was used to create the models and what data is being used for them to continue to learn.
Here are some things to check for when evaluating data:
- Quantity: The more data a model has access to, the better it can learn and perform. Often, it is a sheer numbers game and models trained on more data outperform those with fewer datapoints. State-of-the-art AI models are now trained on hundreds of billions of datapoints.
- Accuracy: “Garbage in, garbage out” applies. Where does the data come from? How do you know it is true and not misinformation? Who labeled the data and was it checked? It’s vital that data is drawn from credible sources.
- Bias: Bias can be caused by a variety of factors, including the data itself, pre-processing techniques used to prepare the data, and the algorithms used to process the data. The data should represent an unbiased cross section.
- Diversity: Ensuring that the data covers a wide range of scenarios, edge cases, and variations can improve the models. Diversity will help ensure the accuracy of the model in real-world implementation.
- Timeliness: How old is the data? Does it represent the current environment? Models will be most effective and potentially more unbiased when trained on current conditions.
- Privacy: If the data is proprietary, how was it collected, stored, and processed? Were all copyrights respected? AI should not introduce new data security issues.
Poor quality data can have serious negative consequences to model quality, so it is essential to consider these factors.
Measurements of fit
To understand fit, we’ll use a chart, called a Confusion Matrix, to show the possibilities and aide in understanding why measurement is important.
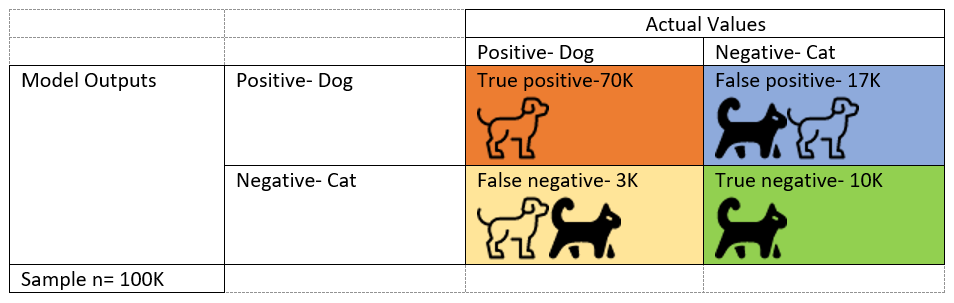
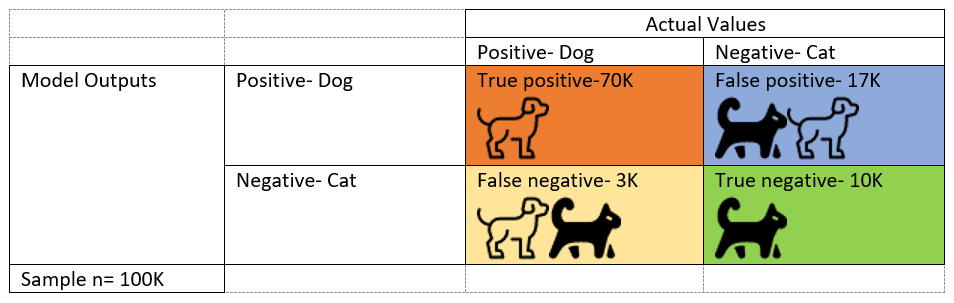
Let’s go back to the example of an AI model that picks dogs. There are two possibilities for actual values: it is a dog, or it is a cat. The model can have two outputs: yes, it is a dog, or no it is not a dog, it is a cat. Hopefully the model is correctly predicting it is a dog when it is, shown in orange, and predicting it is a cat when it is, shown in green. But sometimes it will predict it is a dog when it isn’t, in blue, and sometimes it will say it is a cat when it is a dog, shown in yellow.
There are several common metrics used to evaluate AI algorithms’ performance:
- Accuracy measures the overall performance of the algorithm to correctly predict the output—how often was it right? The model was correct in the orange and green boxes; and if divided by the total, you determine the accuracy is 80%. [(TP+TN)/total => (70+10)/100=80%]
- Precision can be thought of as a measure of exactness. It measures the quality of the positive predictions—when the model said it was a dog, how often was it correct? This is an important measure if false positives need to be avoided. Think of Aesop’s fable about the boy who cried wolf—credibility is lost. Or, if an AI system is used to detect defects in a production line and each positive requires a person to review the piece. Too many false positives would be expensive. [TP/(TP+FP) => 70/(70+17)=80%].
- Recall can be thought of as a measure of completeness. It measures the proportion of actual positives that were identified correctly: how often did the model say an actual dog was a dog? This is significant when overlooked cases are important. For example, if the AI is being used to detect cancer and misses a lot, it could be catastrophic for those misdiagnosed. [TP/(TP+FN) => 70/(70+3)=96%.]
- F1 score is a combination of precision and recall and is used to measure the overall performance of an AI algorithm. A good F1 score means that you have low false positives and low false negatives. [F1 Score = 2*((precision*recall)/(precision+recall) => 2*(.80*.96)/(.80+.96)=.87]
Accuracy is used when the true positives and true negatives are more important; while F1 score is used when the false negatives and false positives are crucial.
There are additional measurements, not covered here, such as Rouge Score, Perplexity, Bleu Score, WER, etc. But the chart above highlights that whatever measurement you use, it needs to measure what is important for how you are going to use AI. A model can have a 95% accuracy measure, which sounds great, and yet not be a good model for your application if the precision is low, meaning a lot of false positives that you can’t tolerate.
Continuous measurements
One way to measure an AI model is to see if it is producing the right outcome when it is functioning in the real world. AI isn’t something you set and forget; it needs to continually be assessed. Even the best models won’t get it right 100% of the time, and even great models can drift over time. AI in practice needs a human in the loop—a human who can provide inputs into how the model is doing to allow the model to learn and correct.
A frequent use case for AI is to help customer service reps handle calls more fully and efficiently. The system can offer suggestions to the rep that they can adopt or not. When the system offers a suggestion that the rep rejects, it learns that those weren’t correct and will learn what works for the company. AI can often help new reps perform at the level of more experienced reps.
A feedback loop is an important part of any AI application.
AI can help us all be more efficient, but only if they work. As discussed above, care needs to be taken at all stages to help ensure quality models that continue to learn.
1089262.1.0




