Ever wondered what’s behind innovative AI applications like ChatGPT? Increasingly, large language models (LLMs) are entering the mainstream and becoming responsible for impressive new technology. But what are LLMs, and how did they get so sophisticated? Let’s break it down.
The objective of any language model is to use existing text (input) to generate new text (output). Exactly how the model interprets input text has changed over time as data access and computing power have increased.
Over the past two years, language models grew exponentially in size, graduating from training on hundreds of data points to hundreds of billions of data points. At such sizes, the moniker large language models, or LLMs, captures an important distinction from these models’ predecessors.
The history of language models
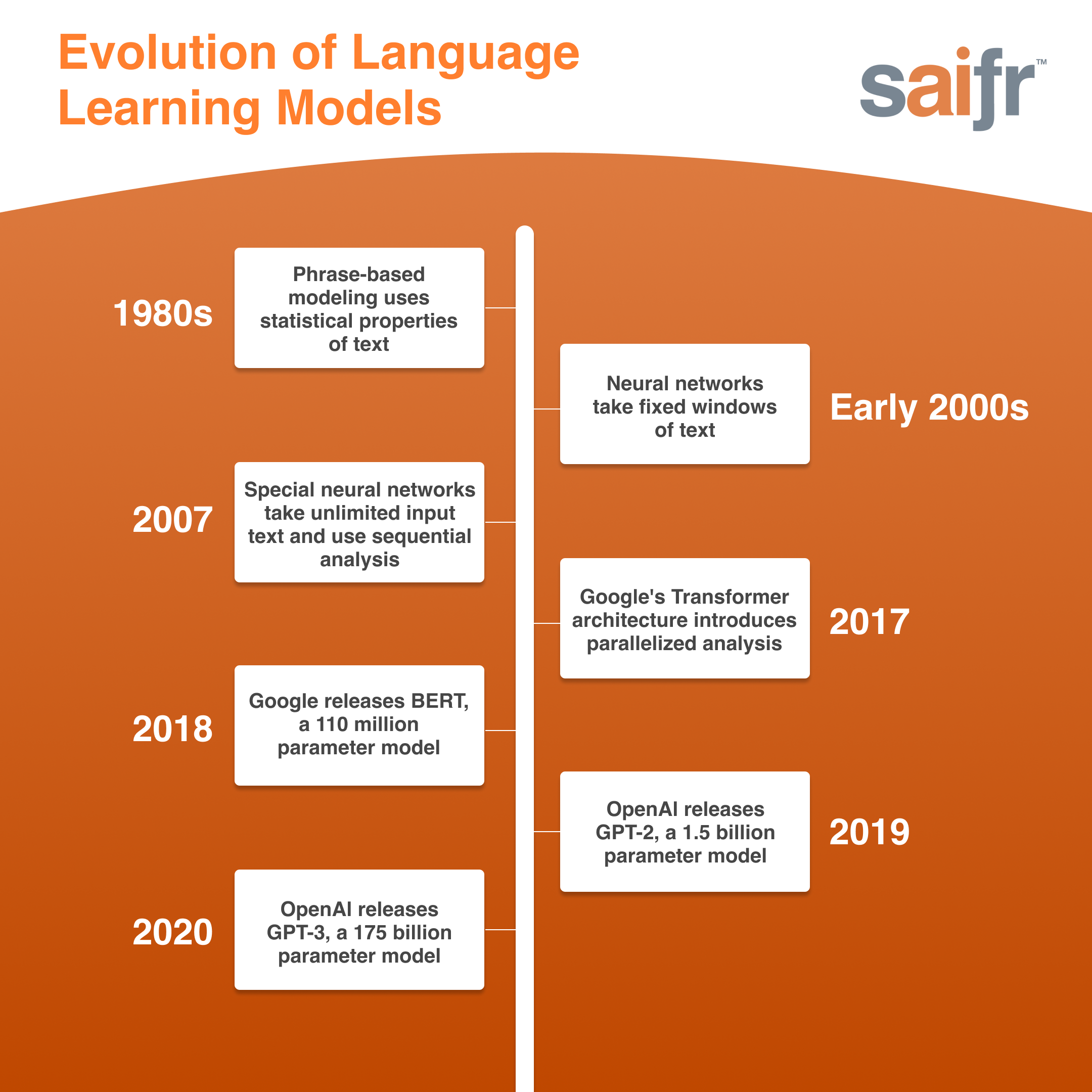
Research into language models can be traced back to the late 1980s. At that time, modeling was driven by the statistical properties of phrases, so output text was computed based on how frequently a word or phrase appeared in input text. The result was that the next output phrase should be the most frequent from the training data. But by nature of this process, rare phrases were biased against. Since common words are not necessarily the ones that convey the meaning of a phrase, this approach usually generated incoherent text.
In the early 2000s, with more available computing resources, phrase-based models were replaced by neural networks, which are a method of AI that simulate how the human brain processes data. Neural networks took a fixed window of text as input, meaning there was a limited amount of language the model could learn from to generate new text. While coherence improved, the fixed window requirement in the input text limited further progress.
In 2007, special neural networks that take input text of unlimited size were created, lifting the fixed-window limitation. These networks utilized sequential analysis—they took one word as input at each time-step but carried over information from the preceding words. This training framework generated text consistent with the input text, leading to improved coherence.
Yet there were still shortcomings. For example, a network trained on input text targeting 5th-graders generated 5th-grade-level text and failed when asked to generate text for executives. The sequential approach to training prohibited more sophisticated textual analysis and limited computing resources. As a result, it took a long time to train diverse and larger datasets.
White paper download → Considering AI solutions for your business? Ask the right questions.
In 2017, the Transformer architecture allowed for parallelized analysis, meaning all the words in a text are analyzed simultaneously, rather than sequentially. This innovation had two major outcomes: it expanded the amount of data/input text the model could train on and it expedited training times. Models could train more data, faster.
From there, things really took off. In 2018, a 110 million parameter language model was released, and in 2019, a 1.5 billion parameter model became available. These language models were powerful, but the quality of text they generated deteriorated after a couple of paragraphs.
In 2020, GPT-3 was released. The new version included even more data: at 175 billion parameters, GPT-3 certainly qualifies as an LLM. Its size, in addition to the larger dataset on which it was trained, enables it to generate longer, higher quality text. Moreover, it is now possible for one model to generate both 5th-grade-level text and executive-level text.
LLMs today
LLMs are powerful. In fact, they can answer almost any random question. The result? Dozens of text-based applications and browser extensions have been developed within the past two months. How performant are they? That’s an open question, but such development speed is unprecedented. Our experience here at Saifr shows that while LLMs can boost development speed, data is crucial to developing a stable solution, especially for complicated tasks.
Are you considering AI solutions for your business? Make sure to ask the right questions.
1076526.1.0




